Keyboard shortcuts:
N/СпейсNext Slide
PPrevious Slide
OSlides Overview
ctrl+left clickZoom Element
If you want print version => add '
?print-pdf' at the end of slides URL (remove '#' fragment) and then print.
Like: https://wwwcourses.github.io/...CourseIntro.html?print-pdf
Created for

Iva E. Popova, 2022-2023,

Проблема "Производител-Потребител"
Проблема "Производител-Потребител"
Описание
- Две нишки, producer() и consumer(), които споделят общ ресурс, който е някакъв артикул.
- Задачата на producer() е да генерира артикула, докато задачата на consumer() е да използва произведената стока.
- Ако артикулът все още не е произведен, то потребителската нишка, трябва да изчака.
- Веднага след като артикулът е произведен, нишката на producer() уведомява потребителя, че ресурсът трябва да бъде използван.
- Забележете, че производителя и потребителя трябва да бъдат синхронизирани.
"Производител-Потребител" - решение чрез "опашка"
import threading
import time
import random
from queue import Queue
BUF_SIZE = 3
q = Queue(BUF_SIZE)
class ProducerThread(threading.Thread):
def __init__(self,name):
threading.Thread.__init__(self)
self.name = name
def run(self):
while True:
if not q.full():
item = random.randint(1,10)
q.put(item)
print(f"Put item: {item} in queue")
time.sleep(random.random())
return
class ConsumerThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
def run(self):
while True:
if not q.empty():
item = q.get()
print(f"Get item: {item} from queue")
time.sleep(random.random())
return
if __name__ == '__main__':
p = ProducerThread(name='producer')
c = ConsumerThread(name='consumer')
p.start()
# time.sleep(2)
c.start()
# time.sleep(2)
Паралелно Програмиране - "Мъртва Хватка"
Паралелно Програмиране - "Мъртва Хватка"
Какво е "Мъртва Хватка"
- В практиката, когато Нишки или Процеси използват общи ресурси може да се получи т.нар. мъртва хватка.
- В най-простия случай, мъртва хватка се получава когато един Процес/Нишка очаква достъп до ресурс, който е "заключен" от друг Процес/Нишка, и същевренно втория Процес/Нишка очаква достъп до ресурс, "заключен" от първия Процес/Нишка.
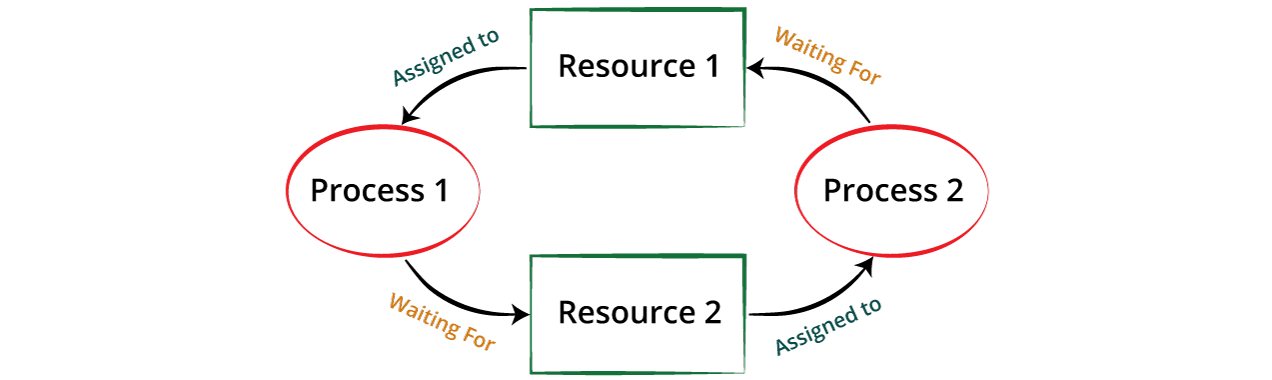
- Процес 1 очаква достъп до Ресурс2, преди да продължи работата си
- Процес 2 очаква достъп до Ресурс1, преди да продължи работата си
- Настъпва "мъртва хвата" - и двата процеса остават взаимно блокирани
"Мъртва Хватка" - Пример
import threading
import time
l1=threading.Lock()
l2 = threading.Lock()
def f1(name):
with l1:
print('thread',name,'has lock l1')
time.sleep(0.5)
with l2:
print('thread',name,'has lock l2')
print('thread',name,'run into deadLock,\nthis line will never run')
def f2(name):
with l2:
print('thread',name,'has lock l2')
time.sleep(0.3)
with l1:
print('thread',name,'has lock l1')
print('thread',name,'run into deadLock,\nthis line will never run')
if __name__ == '__main__':
t1=threading.Thread(target=f1, args=['t1',])
t2=threading.Thread(target=f2, args=['t2',])
t1.start()
t2.start()
Използване на with оператора за получаване/освобождаване на lock
- Всички lock обекти, които има
acquire()/release()методи могат да се използват с оператораwithкато контекст мениджъри.
# записът:
with some_lock:
# do something...
# е еквивалентно по функционалност на:
some_lock.acquire()
try:
# do something...
finally:
some_lock.release()
Паралелно Програмиране - Примери
Паралелно Програмиране - Примери
Сваляне на множество файлове - requests library
- Чрез библиотеката
requestsможем да свали даден HTTP ресурс - Документация: docs.python-requests.org
import requests
url = "https://unsplash.com/photos/CTflmHHVrBM/download?force=true"
file_name = url.split('/')[4]+".jpg"
# get image bytes
print(f"Start downloading {url}")
response = requests.get(url)
# write image to file
with open(file_name, 'wb') as fh:
fh.write(response.content)
print(f"File saved to {file_name}")
Сваляне на множество файлове - задача
- Използвайки посочения пример, съставете програма която да свали всички изображения от посочените адреси
"https://unsplash.com/photos/CTflmHHVrBM/download?force=true"
"https://unsplash.com/photos/pWV8HjvHzk8/download?force=true"
"https://unsplash.com/photos/1jn_3WBp60I/download?force=true"
"https://unsplash.com/photos/8E5HawfqCMM/download?force=true"
"https://unsplash.com/photos/yTOkMc2q01o/download?force=true"
Сваляне на множество файлове - решение
import requests
import os
import time
def download_file(url):
file_name=url.split('/')[4]+'.jpg'
full_file_name = os.path.join(download_path,file_name)
# get image bytes
print(f"Start downloading {url}")
response = requests.get(url, allow_redirects=True)
# write image to file
with open(full_file_name, 'wb') as fh:
fh.write(response.content)
print(f"File saved to {full_file_name}")
urls = [
"https://unsplash.com/photos/CTflmHHVrBM/download?force=true",
"https://unsplash.com/photos/pWV8HjvHzk8/download?force=true",
"https://unsplash.com/photos/1jn_3WBp60I/download?force=true",
"https://unsplash.com/photos/8E5HawfqCMM/download?force=true",
"https://unsplash.com/photos/yTOkMc2q01o/download?force=true"
]
download_path = os.path.join(os.getcwd(),"downloaded_images")
if __name__ == "__main__":
start= time.perf_counter()
for url in urls:
download_file(url)
end = time.perf_counter()
print(f"Procesing time: {end-start}")
Сваляне на множество файлове чрез нишки - задача
- Съставете програма, която да свали посочените изображения като използвате Нишки
Сваляне на множество файлове чрез нишки - решение
import threading
import requests
import os
import time
def download_file(url):
file_name=url.split('/')[4]+'.jpg'
full_file_name = os.path.join(download_path,file_name)
# get image bytes
print(f"Start downloading {url}")
response = requests.get(url, allow_redirects=True)
# write image to file
with open(full_file_name, 'wb') as fh:
fh.write(response.content)
print(f"File saved to {full_file_name}")
urls = [
"https://unsplash.com/photos/CTflmHHVrBM/download?force=true",
"https://unsplash.com/photos/pWV8HjvHzk8/download?force=true",
# "https://unsplash.com/photos/1jn_3WBp60I/download?force=true",
# "https://unsplash.com/photos/8E5HawfqCMM/download?force=true",
# "https://unsplash.com/photos/yTOkMc2q01o/download?force=true"
]
download_path = os.path.join(os.getcwd(),"downloaded_images")
if __name__ == "__main__":
start= time.time()
threads = []
# create and start a thread per each url
for url in urls:
tr = threading.Thread(target=download_file,args=(url,))
threads.append(tr)
tr.start()
# result= download_file(url)
# join all threads
for tr in threads:
tr.join()
end = time.time()
print(f"Procesing time: {end-start}")
Сваляне на множество файлове чрез ThreadPoolExecutor
- В python 3.2 се въвежда модула concurrent.futures, които предлага абстракция при работа с асинхронни задачи.
- ThreadPoolExecutor e подклас на класа Executor в модула
concurrent.futuresкойто абстрахира работата със създаване и стартиране на множество нишки (а също така и процеси)

Сваляне на множество файлове чрез ThreadPoolExecutor
- В примера е използван метода
map()на concurrent.futures.Executor класа, който работи по подобен начин на стандартнатаmap(func, *iterables)функция, с тази разлика, че подадената функцияfuncсе изпълнява асинхронно (чрез нишки или процеси)
import requests
import concurrent.futures
import os
import time
def download_file(url):
file_name=url.split('/')[4]+'.jpg'
full_file_name = os.path.join(download_path,file_name)
# get image bytes
print(f"Start downloading {url}")
response = requests.get(url, allow_redirects=True)
# write image to file
with open(full_file_name, 'wb') as fh:
fh.write(response.content)
print(f"File saved to {full_file_name}")
urls = [
"https://unsplash.com/photos/CTflmHHVrBM/download?force=true",
"https://unsplash.com/photos/pWV8HjvHzk8/download?force=true",
"https://unsplash.com/photos/1jn_3WBp60I/download?force=true",
"https://unsplash.com/photos/8E5HawfqCMM/download?force=true",
"https://unsplash.com/photos/yTOkMc2q01o/download?force=true"
]
download_path = os.path.join(os.getcwd(),"downloaded_images")
if __name__ == "__main__":
start= time.perf_counter()
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(download_file, urls)
end = time.perf_counter()
print(f"Procesing time: {end-start}")